NVIDIA & AMD — NATIVE DUAL-PLATFORM SUPPORT
Checkpointing That
Doesn't Stop Training.
The async I/O engine that eliminates GPU idle time during checkpointing. 16+ GB/s effective throughput verified on NVIDIA Blackwell (RTX 5080), H100/B200 and AMD MI300X with bit-perfect integrity. Native low-level binaries for Linux & Windows.
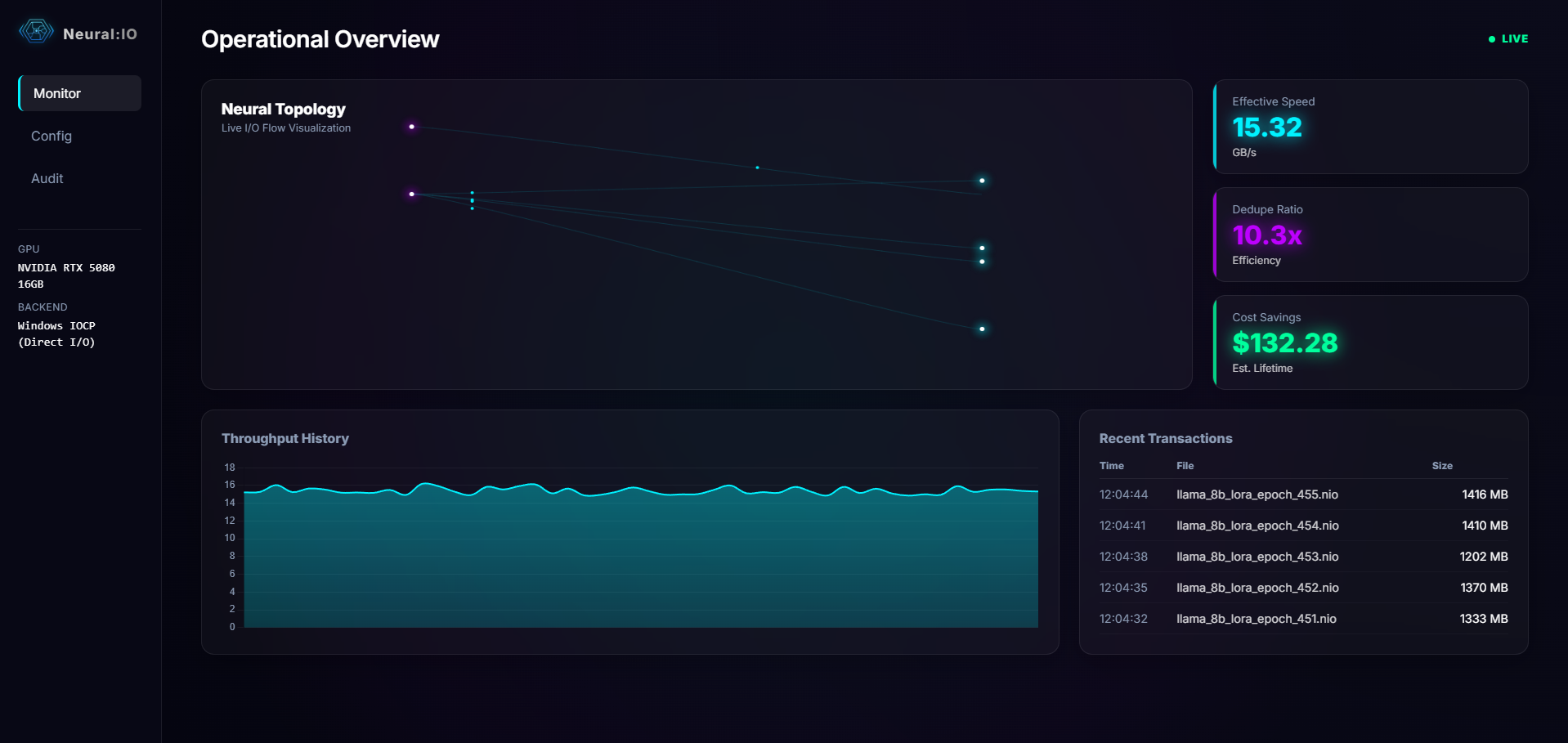
Effective Throughput
16+ GB/s
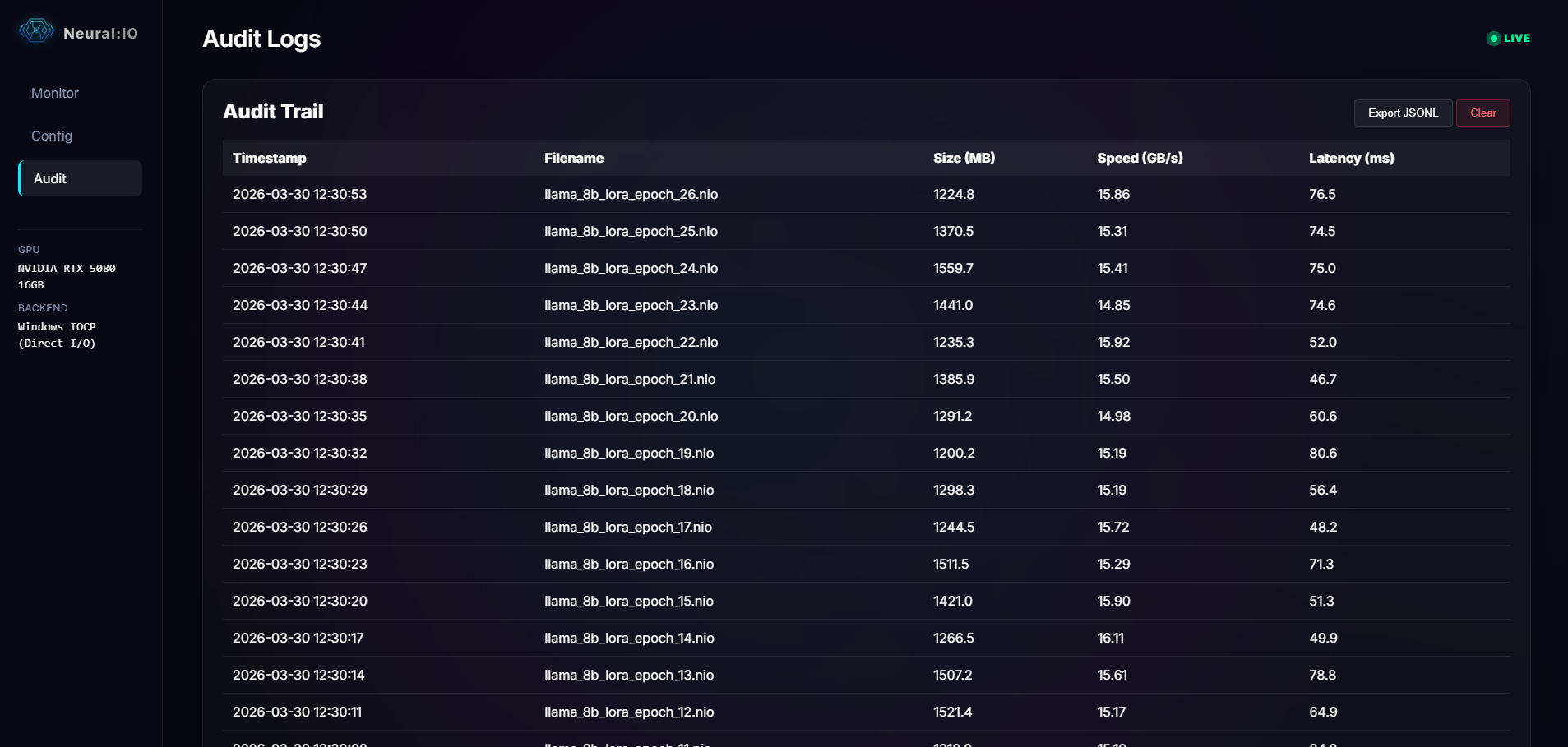
Verified effective write speed on RTX 5080. Near-zero I/O overhead for incremental checkpointing through asynchronous hardware-native pipelining.
Efficiency & Integrity
10x+ Deduplication
Bit-Perfect Accuracy: Atomic commitment guarantees 100% restoration.
10x+ Ratio: Validated on LLaMA 8B sharded checkpoints and LoRA workloads.
Enterprise Ready & Hardware Native
NVIDIA + AMD
Python 3.10–3.12 Support
NVIDIA: Native support for Hopper, Blackwell, Ampere, Turing. Fat binary: SM75→SM100+PTX
AMD: Native ROCm 6.x for MI300X (gfx942) and MI250X (gfx90a).
AMD: Native ROCm 6.x for MI300X (gfx942) and MI250X (gfx90a).
Distributed: DDP and FSDP natively supported. Slurm compatible.
Backends: Native io_uring (Linux) and IOCP (Windows). Fully offline operation for enterprise.
Backends: Native io_uring (Linux) and IOCP (Windows). Fully offline operation for enterprise.
DeepSpeed and HF Accelerate native interception planned — contact us to prioritise.